
One of the big challenges of large AI clusters is keeping the GPUs working at their maximum. Some may think of AI workloads as keeping GPUs at 100% for months on end. In reality, the GPU workloads are more like a series of peak loads, then valleys. That is one reason high-speed networking is so important for GPU-to-GPU communication because it minimizes the valleys. Today, NVIDIA shared some of the things it is doing to help lessen the challenge of those valleys.
NVIDIA Starts to Tackle GPU Power Smoothing with the NVIDIA GB300 NVL72
NVIDIA showed this as an AI training workload looks like from a power perspective. As you can see, there are periods of heavy work, followed by more idle times.
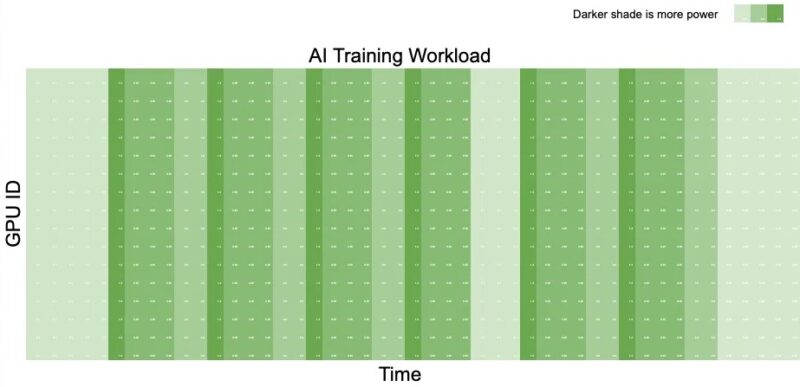
If you do not know this, when you have huge numbers of GPUs that transition from peak to valley can cause huge delta values in power being used. As a result, if you have something that needs to spin to power your cluster (e.g. a diesel generator, turbine, or something of that nature) the pattern above is very stressful since the power generation needs to quickly respond to the peaks and valleys of power.
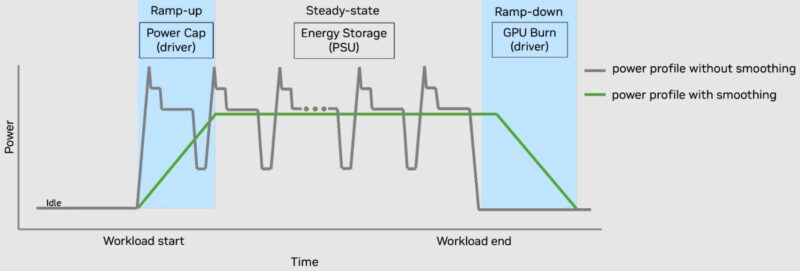
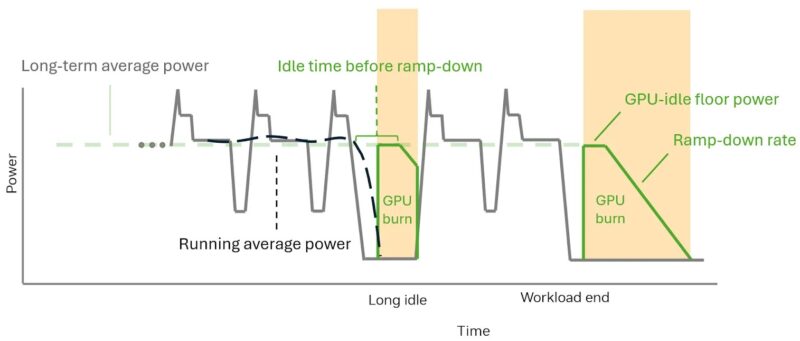
Ideally, you do not want to have to generate peak power. Instead, you want to have some sort of capacitance in the AI cluster to keep it running. The goal is to generate closer to the average power and then storing charge during the valleys to be used on the peaks. There are a number of ways to help even the load. One of the interesting ones that NVIDIA is doing is now a GPU burn. This helps to even out the load in the system by keeping the GPUs active. This is somewhat of a crazy idea if you think about it, but one that several have come up with to help solve the peak and valley problem.
NVIDIA also has added things like more capacitance in its power supplies. That helps even the load as well. For example, here is Megatron LLM running on both the GB200 and the GB300 where you can see similar DC outputs, but the AC inputs are much flatter.
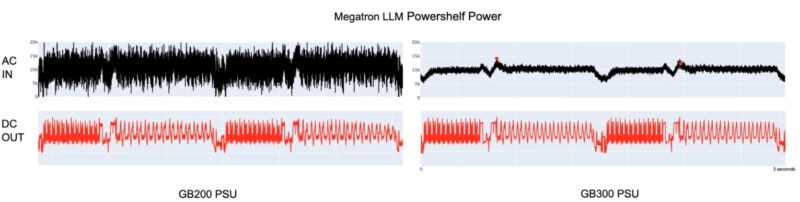
All of this is to help smooth the power usage.
Final Words
A few months ago, we featured LITEON showing NVIDIA GB200 NVL72 Rack at OCP Summit 2024. There were a number of components there, including batteries in the power racks to help even the load from GPUs. We have even shown large battery packs used to help this in data centers.
Still, it is a huge challenge to have so many GPUs spike power like this, especially in the largest clusters. As a result, we expect more batteries to make their way into AI data centers, and more steps to help flatten the load across large clusters. It was neat that NVIDIA shared this step today.



{kind=link}
AI needs much more to not burn the Power-Grid:
https://www.nerc.com/comm/RSTCReviewItems/3_Doc_White%20Paper%20Characteristics%20and%20Risks%20of%20Emerging%20Large%20Loads.pdf
https://www.datacenterdynamics.com/en/news/ai-data-centers-causing-distortions-in-us-power-grid-bloomberg/
Quick note: You have the same image at the top of the article twice in a row, with different descriptions, and different links. Was it supposed to be two different, unique images?
As a note, what ever happened to “Ultra capacitors” or “Super capacitors” for systems like this? The whole idea was they were perfect for long term power smoothing, and they don’t die like batteries.
Batteries would be good for power support during outages, but for smoothing, something like Maxwell ultra capacitors would be much better I would think.
@James Ultracapacitor energy density is extremely low compared to batteries, so they are often impractical in size-constrained environments. Typically they are only worthwhile when you need to charge or discharge very quickly (many hundreds of amps), such as for spot welding. For power smoothing you need to store a large amount of energy and they are just too physically large for that – for example you could double the size of the PCIe card and only gain enough energy storage to run it for a few minutes, so it wouldn’t really be able to do much in the way of smoothing.