
SiFive has a new family of RISC-V CPUs out that naturally cater to AI applications. The new SiFive 2nd Gen Intelligence Family has additional models at a lower size and power footprint while also adding new features to larger IP blocks.
SiFive 2nd Gen Intelligence Family Launched
Something I did not know before this was that the RISC-V accelerator IP is ramping quite quickly. RISC-V is seemingly everywhere these days. Folks talk about Arm and NVIDIA with Grace and BlueField, but RISC-V is in many NVIDIA designs now.
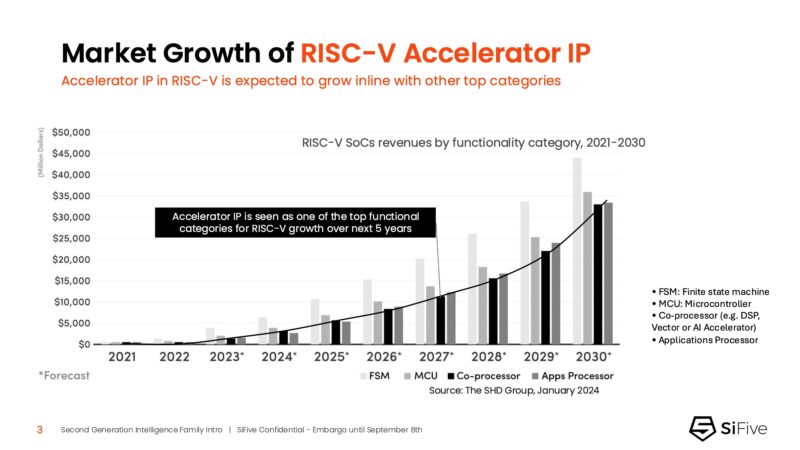
SiFive has IP for its 1st Gen Intelligence family that ranged from the X200 to XM series. This included things like the scalar compute cores, but also big vector and matrix engines. One can then use these designs in clusters to build bigger AI chips, or use standalone IP blocks to make lower power control nodes.

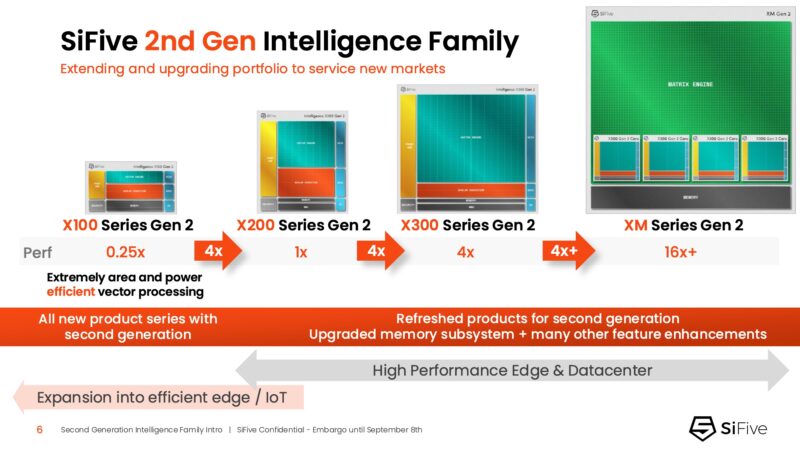
The new generation adds a smaller core, for lower-power and control applications along with bringing new features to the range.
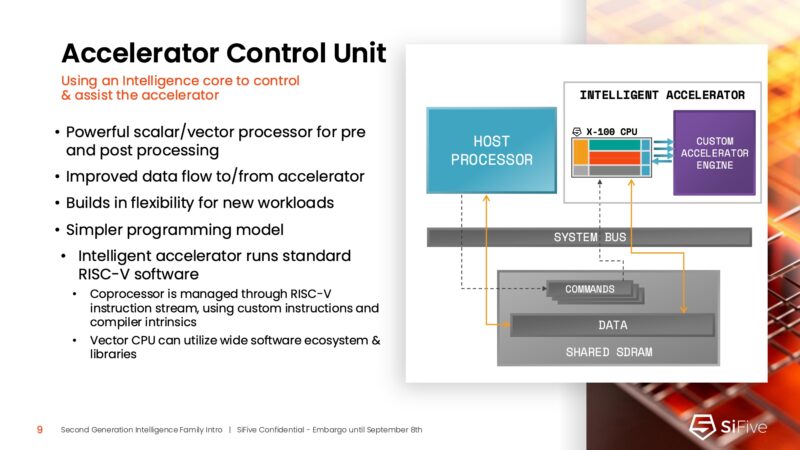
One of the big areas of IP is the accelerator control unit. This is actually an area that RISC-V is used quite a bit today. The small X100 IP is seen as a way to offload control tasks from the host CPU to the accelerator.
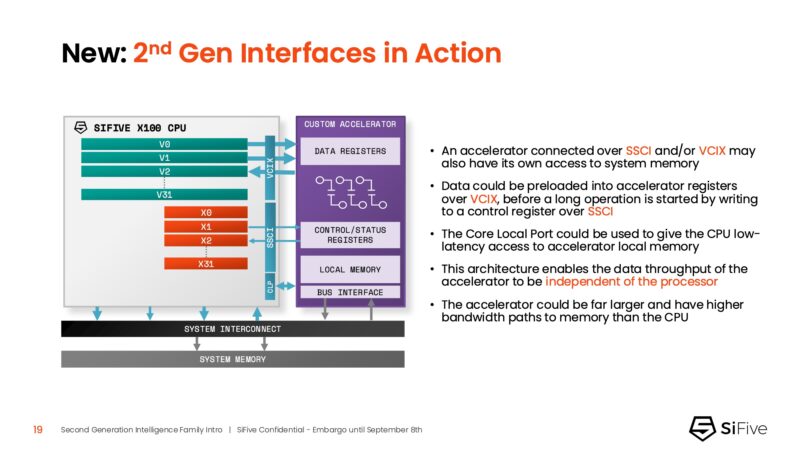
The IP has both the SSCI and VCIX to connect to accelerators. For example, the SSCI or SiFive Scalar Coprocessor Interface has direct access to CPU registers and can drive accelerators via custom instructions. The VCIX or Vector Coprocessor Interface provides high-bandwidth access to CPU vector registers.
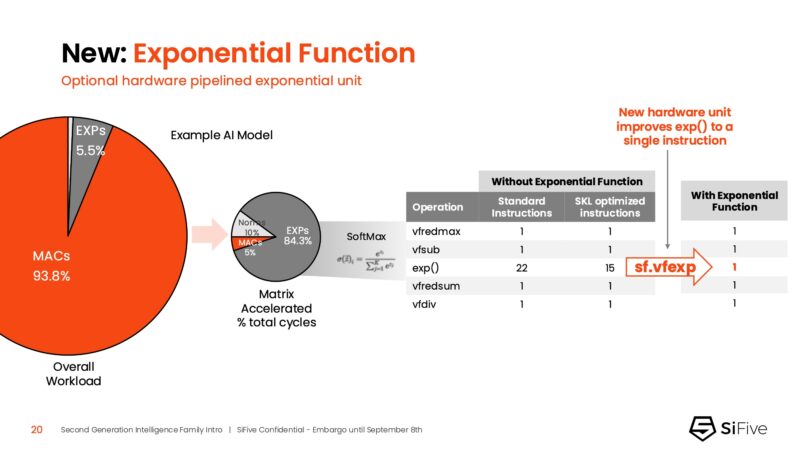
The new SiFive IP has a new exponential function taking an exponential function from 15-22 instructions down to 1. While that may be a smaller amount of raw compute compared to what the MAC units do, it is a way to make that small portion operate a lot faster.
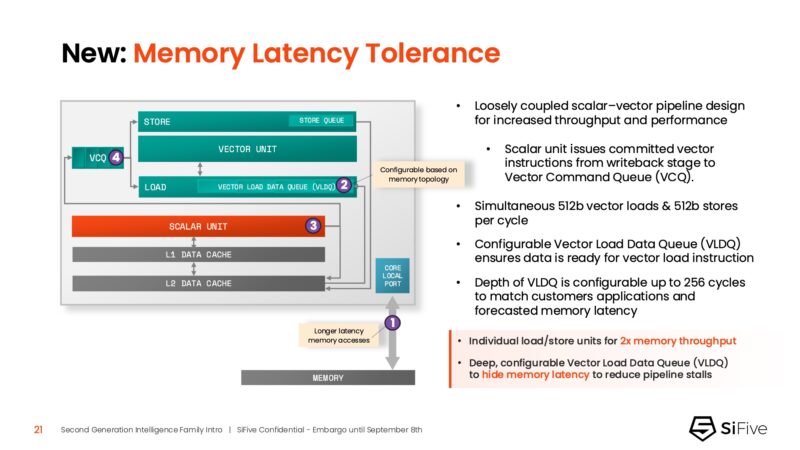
Since SiFive has a loosely coupled scalar-vector pipeline, it can use features like a configurable VLDQ to effectively hide memory latency for well-known workloads. A good example of this is when you have a control application and know the range of parameters of the system.
SiFive also changed from having a L3 cache to an optional shared L2 cache that is 1MB like the L3 cache was. This increases the utilization of the caches while giving back die area.

As a family of IP, this is expected to scale, so here is SiFive’s scaling from a single small controller core to multiple big matrix XM cores being used for an AI accelerator.
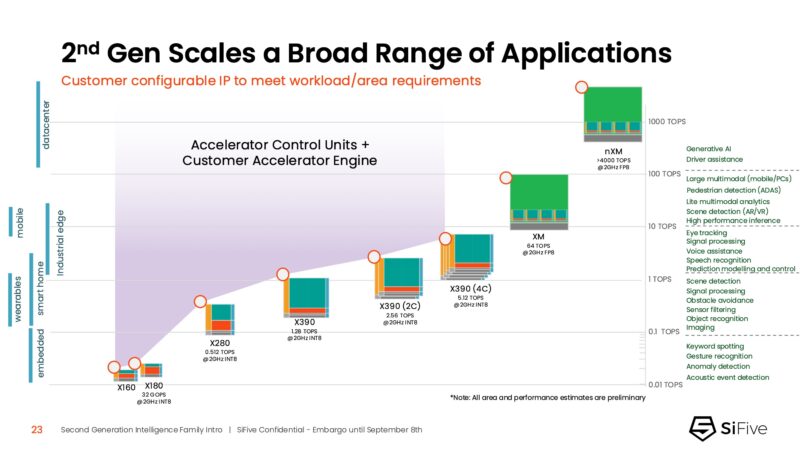
Here is the scaling chart between the X100, X200, X300, and XM IP in this generation.

The X100 is the smaller variant and it can come in 64-bit or even 32-bit. 32-bit is still popular in a lot of embedded applications because of the memory savings.

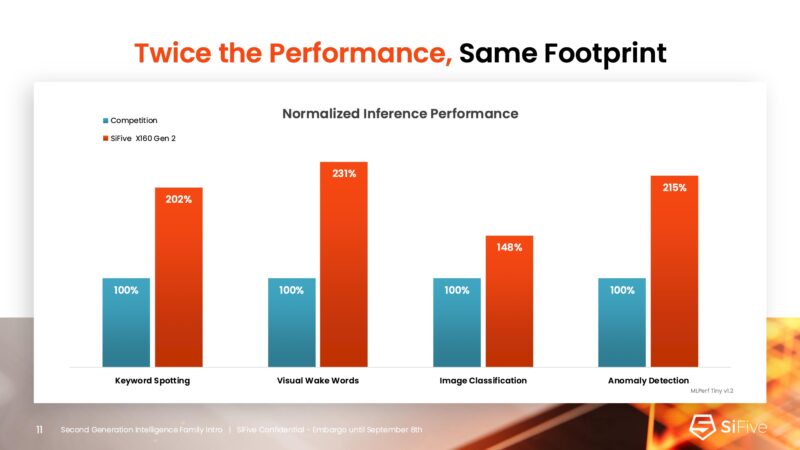
SiFive did not say that they are better than something like an Arm core or a Xeon D/ Atom core, so just saying competition here is a bit of a bummer. Of course, it is a challenge to compare an existing product that has not just cores, but also accelerator IP and I/O interfaces to a core IP. Still, hopefully SiFive can have competitive performance in the future.
The X280 is the next step up. Here we have things like RVA23 support which is a big one. RVA23 a standard specification for 64-bit RISC-V processors that provides a consistent set of minimum base instructions. One of the big kocks on RISC-V over the years is that everyone was designing to their own needs, so having standards necessary to make the software side easier was lacking. RVA23 is the big step in making the software and compatibility side better.

The X390 is the next step up in performance.

The XM is the version that integrates four of the X300 cores but then has a big XM Gen2 matrix engine.

If you wanted to build a big AI accelerator with SiFive’s matrix engine, you would probably use the XM series.
Final Words
SiFive is pushing to have a new generation of cores so that they can find their way into a number of devices in the next design cycle. Something that is probably understated here is that SiFive’s value proposition is that it creates this off-the-shelf IP, in some ways similar to Arm. At the same time, if a company wants to in the future, it is free to use RISC-V and make its own designs without the licensing of Arm ecosystems. That is one of the reasons that RISC-V is taking over a lot of the control planes in even larger systems. For example, as much as NVIDIA is using Arm for customer facing cores, things like the Data Path Accelerator in its ConnectX-8 NICs are actually based on RISC-V.




{kind=link}