
At STH, we have been covering the Cavium, now Marvell ThunderX line since 2016. Today, Marvell is giving an update on their ThunderX2 progress and divulging details on the upcoming ThunderX3 family. Get ready, the Arm ecosystem is about to have a 96 core 384 thread per socket processor. If you thought the Ampere Altra Q80-30 with 80 cores and 80 threads was a lot, this is even bigger.
ThunderX Evolution
The Marvell ThunderX journey started in 2016. At the time, we said it ARM developers need these machines. The solution went from being extremely difficult to use in March 2016 to very usable, albeit often not optimized for performance in April 2016 with the Ubuntu 16.04 LTS release. When our ThunderX2 review went live in 2018, it was the defacto Arm server option on the market. Still, that was a 2018 part and we now have the AMD EPYC 7002 Series Rome and the 2nd Gen Intel Xeon Scalable Refresh on the x86 side along with chips like the AWS Graviton2 in the cloud. Frankly, in the CPU business, you need to iterate on platforms and it is time that the ThunderX family gets its third-generation refresh.
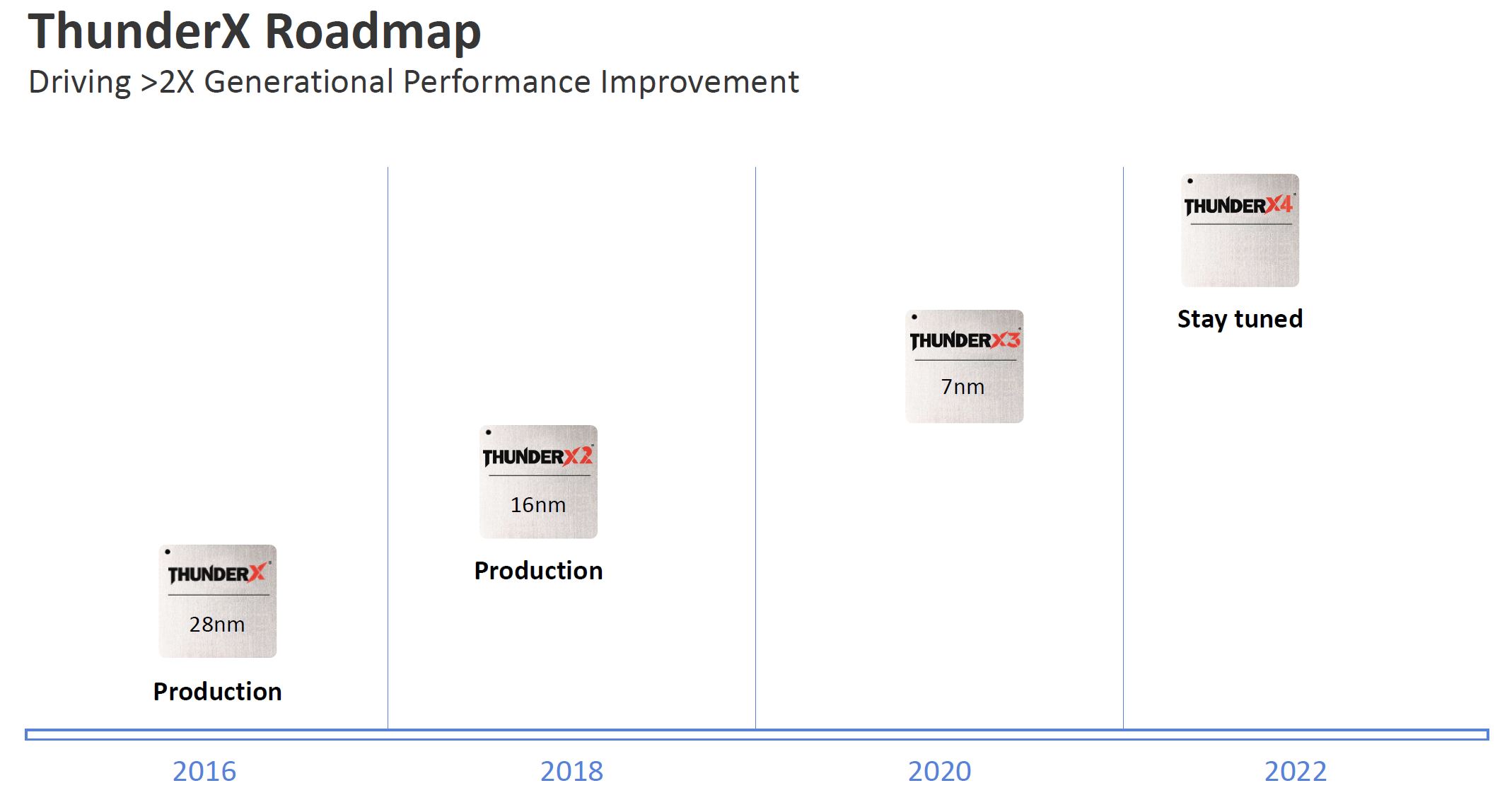
Marvell says to expect ThunderX3 later 2020 in terms of volume production and platforms. One benefit it has over companies like Ampere is that Marvell is a larger organization with more silicon to potentially bundle, and it has generations of working with vendors on current platforms. Some may point to eMAG but that is closer to a ThunderX (1) device than a ThunderX2 device so Ampere is essentially doing a 2017-era AMD and re-entering the server market. You can see on the difference between the Naples and Rome launch platform diversity as well as Intel’s lead in the number of platforms available, so time in market matters.
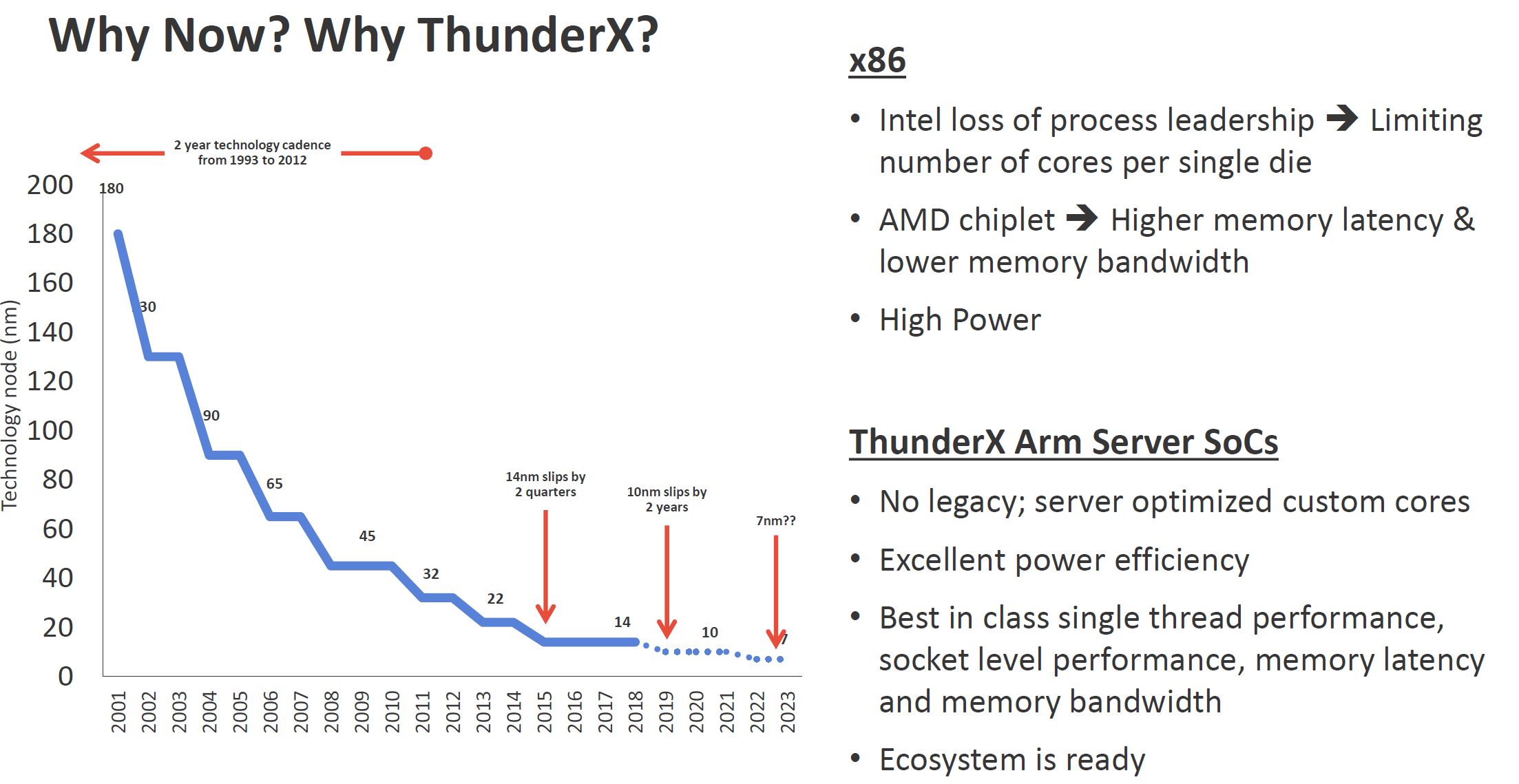
Marvell now is saying that Intel has essentially lost its process leadership as Ice Lake Xeons slip. 7nm AMD chiplets Marvell notes the latency penalty and still thinks monolithic is better. This is despite the silicon industry and even its fab partner TSMC saying chiplets will be the way forward. One can guess that if Marvell was doing multi-die here that bullet would look different. Marvell thinks Arm SoCs without legacy instructions can deliver what the industry needs going forward.
Talking about the ecosystem, Marvell wanted to point out that it has been winning with ThunderX2 in the hyperscale and HPC markets.

The company is highlighting ThunderX2 deployments ranging from Microsoft Azure to a number of supercomputers, Some we covered such as a 4096 Core HPE Deployment.

STH asked about ThunderX2 in Exascale, specifically not having any wins on the first three US systems. We were told to stay tuned and that one of the biggest blockages was not having a GPU solution. Arm teaming with NVIDIA is the ThunderX3 and ThunderX4’s way to counteract Intel and AMD both with GPUs.

Overall, the ecosystem has come a long way from when STH started covering ThunderX in 2016.
Marvell ThunderX3
The Marvell ThunderX3 will have up to 96 cores with 4-way SMT for up to 384 threads per socket. These cores are Arm v8.3+ which means they have future features pulled in. They are also custom designed. Ampere is using more standard Arm Neoverse N1 cores which is why they do not have SMT functionality (although Ampere says it is a feature.) That is a big deal as Marvell is offering real differentiation by not using stock, or near-stock, Neoverse cores in their design. Going this route means ThunderX3 can differentiate itself in the market to a higher degree.
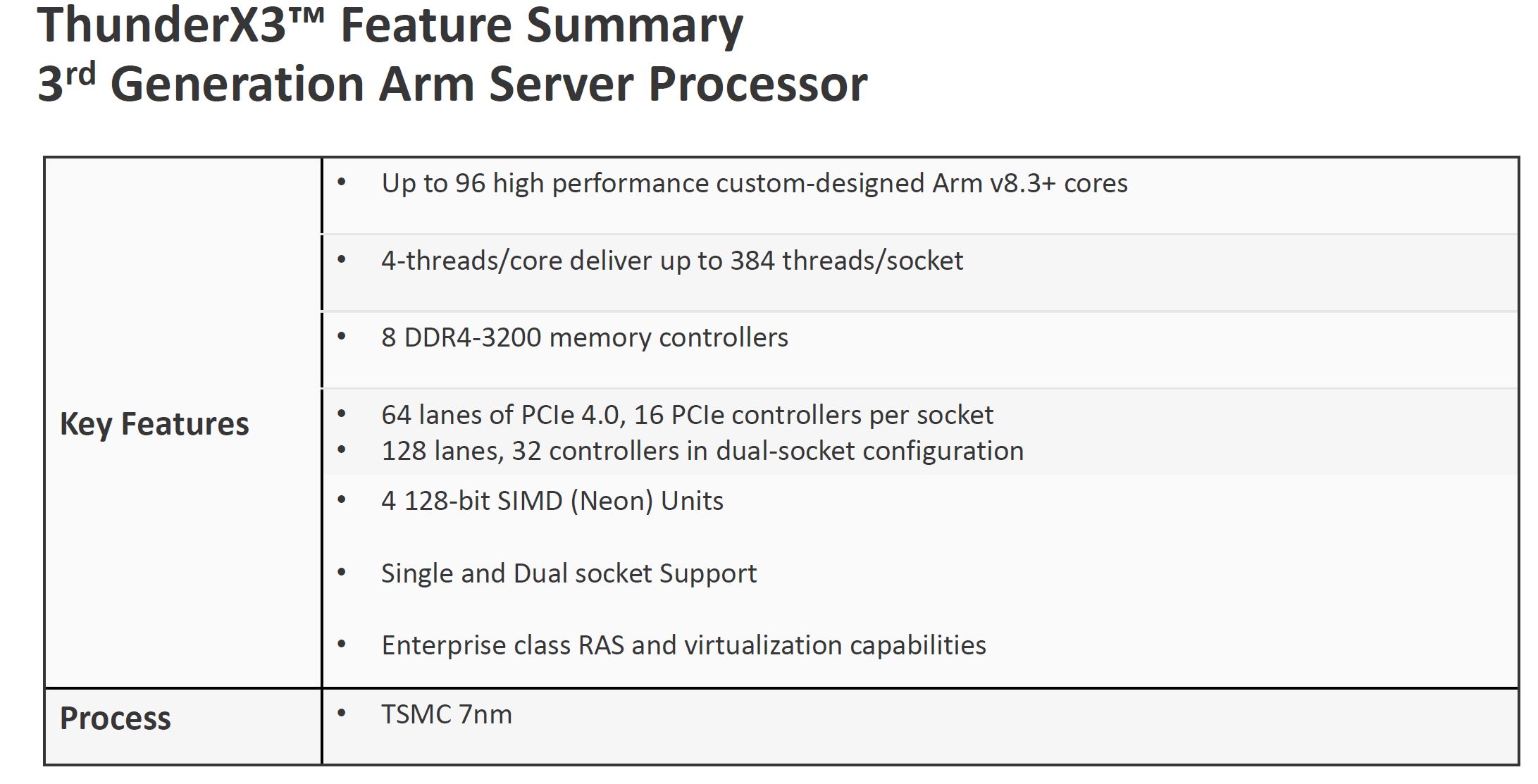
The key here is that there are 8x DDR4-3200 memory controllers and PCIe Gen4 support. One gets 64x PCIe Gen4 lanes per CPU either in single or dual-socket configurations so it is more like current Intel Xeon CPUs than AMD EPYC and Ampere Altra. There are also four 128-bit SIMD units onboard. What this all means is that Marvell is predicting massive performance gains.
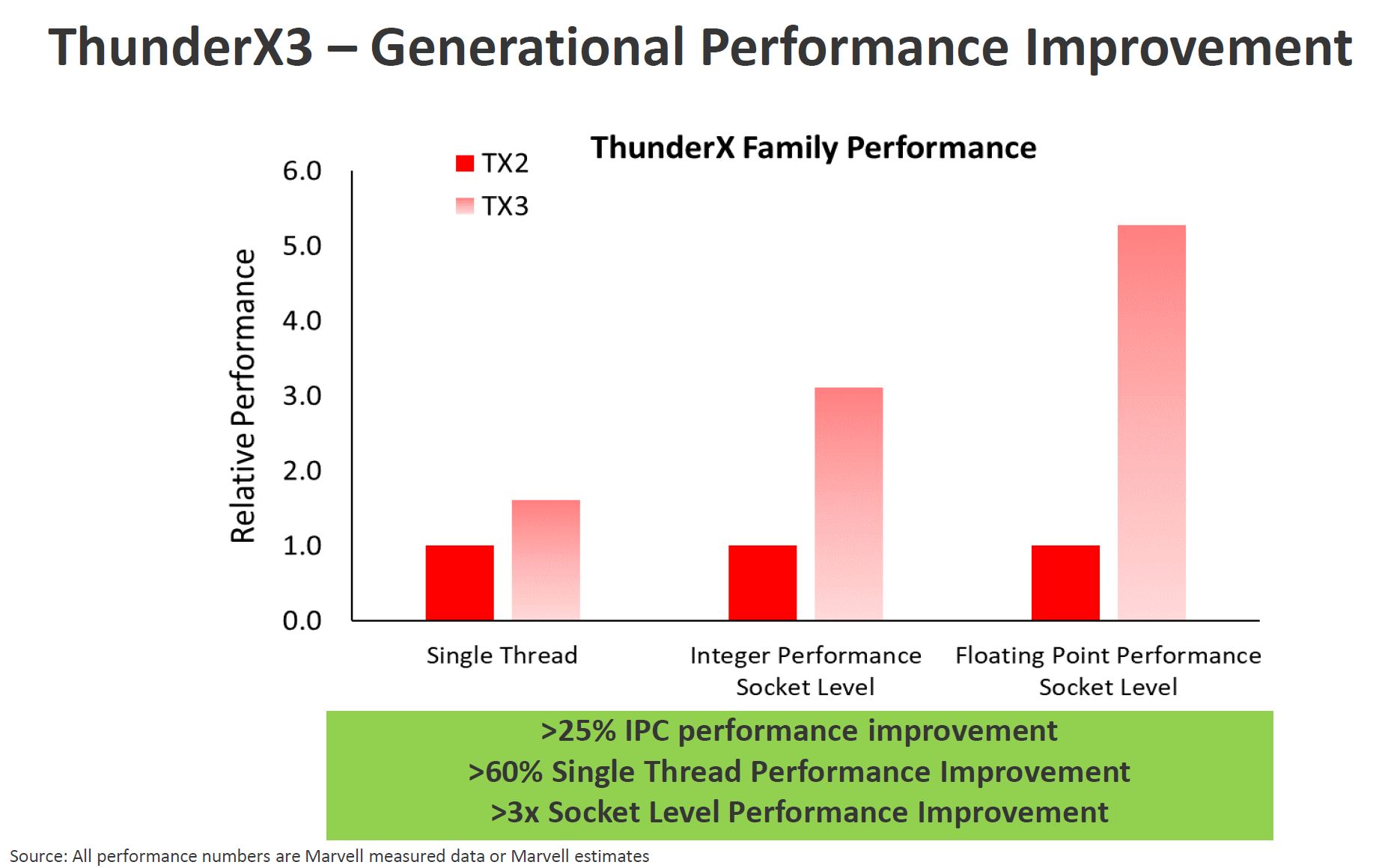
Marvell is specifically targeting key areas of the performance arena including more than 60% per-thread performance from IPC (25%) and clock speed gains. The company also sees about 3-6x performance on the integer and floating point sides on the socket-level. One should remember here that the cores counts are tripling on a per-socket basis with the 16nm to 7nm shrink so this makes sense. Marvell is also going after three primary markets: cloud, HPC, and Arm-on-Arm.

We are going to talk about all three of these workloads next. We will note that you can see Arm-native as an extension or subset of the “Cloud” segment.
Marvell ThunderX3 for Cloud
On the cloud workload side, it is showing off its PCIe Gen4 advantage over Intel, along with more cores and threads. It also is focusing on the AMD EPYC chiplet architecture’s extra I/O die hop for memory latency while conveniently saying that the cache does not help for cloud workloads.
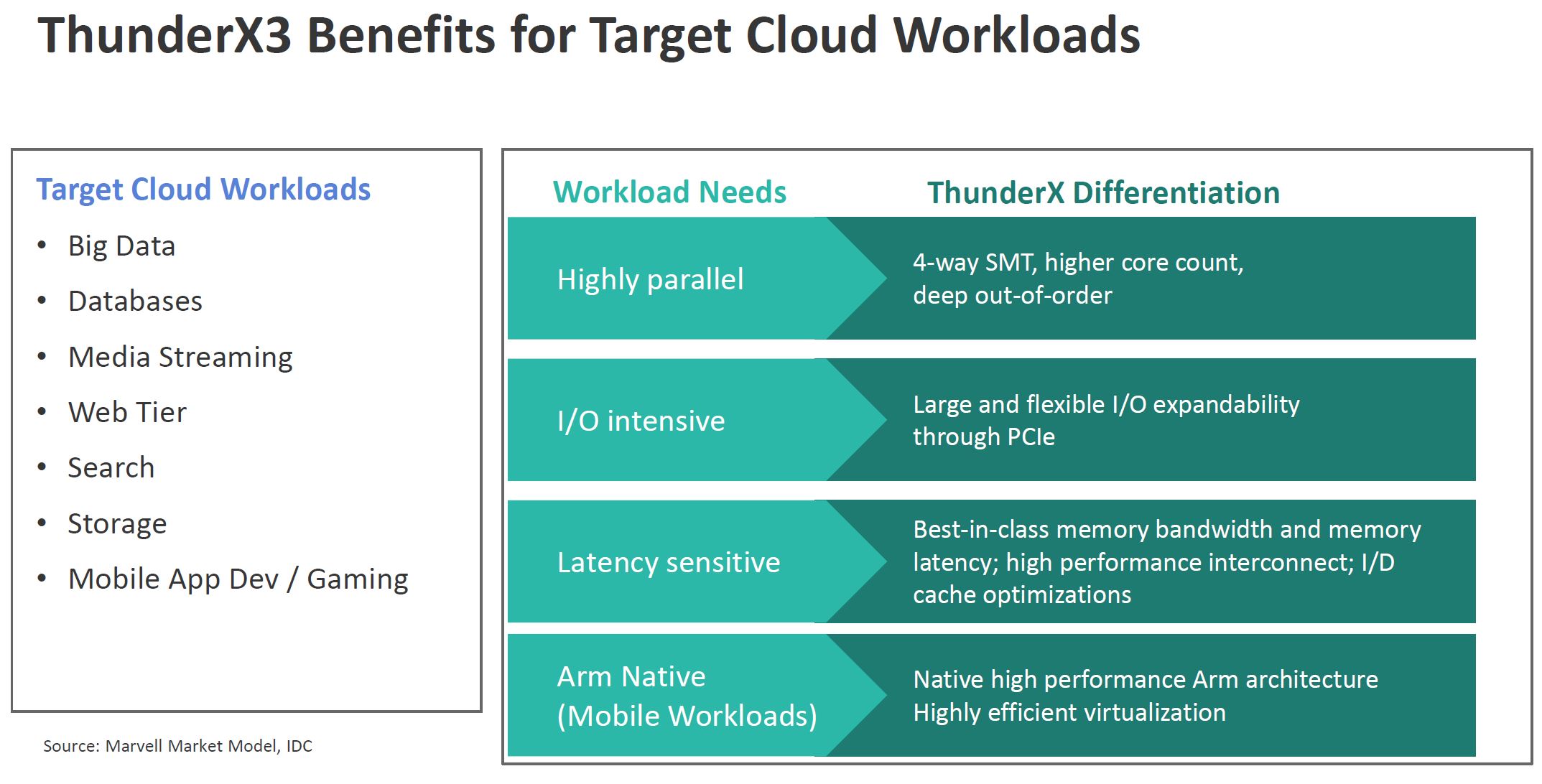
Interestingly enough, while Ampere touts not having SMT as a consistency advantage for the cloud, Marvell says that the parallel nature of SMT is important. It shows significant gains with SMT=4 v. SMT=1.
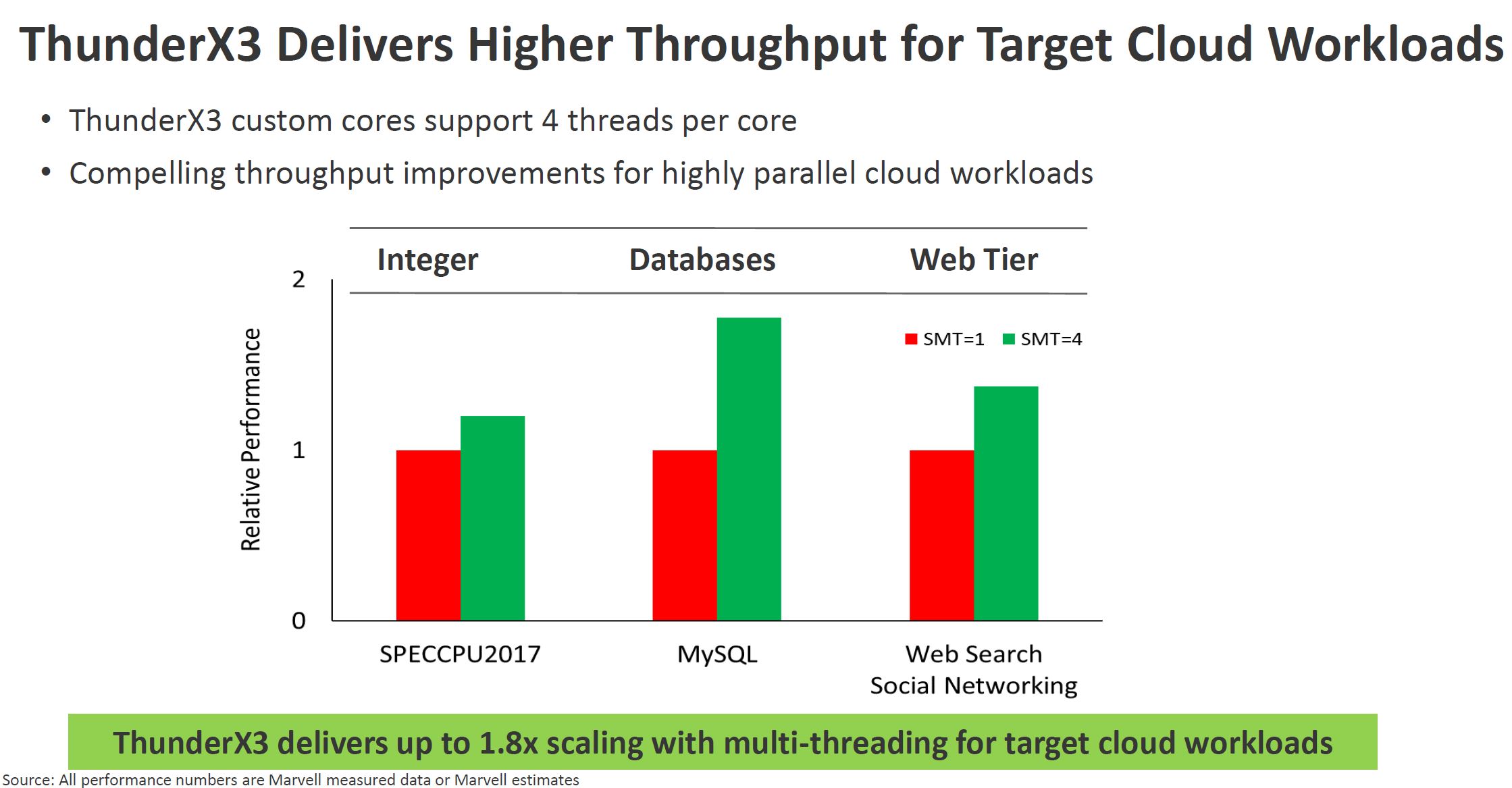
Marvell has EPYC 7742 and Xeon Platinum 8280 systems in its lab and says that ThunderX3 should out-perform both. That brings a question to whether TX3 will beat the next-gen AMD EPYC 7003 series “Milan” but there it may still hold an advantage over Intel Xeon Ice Lake generation chips.
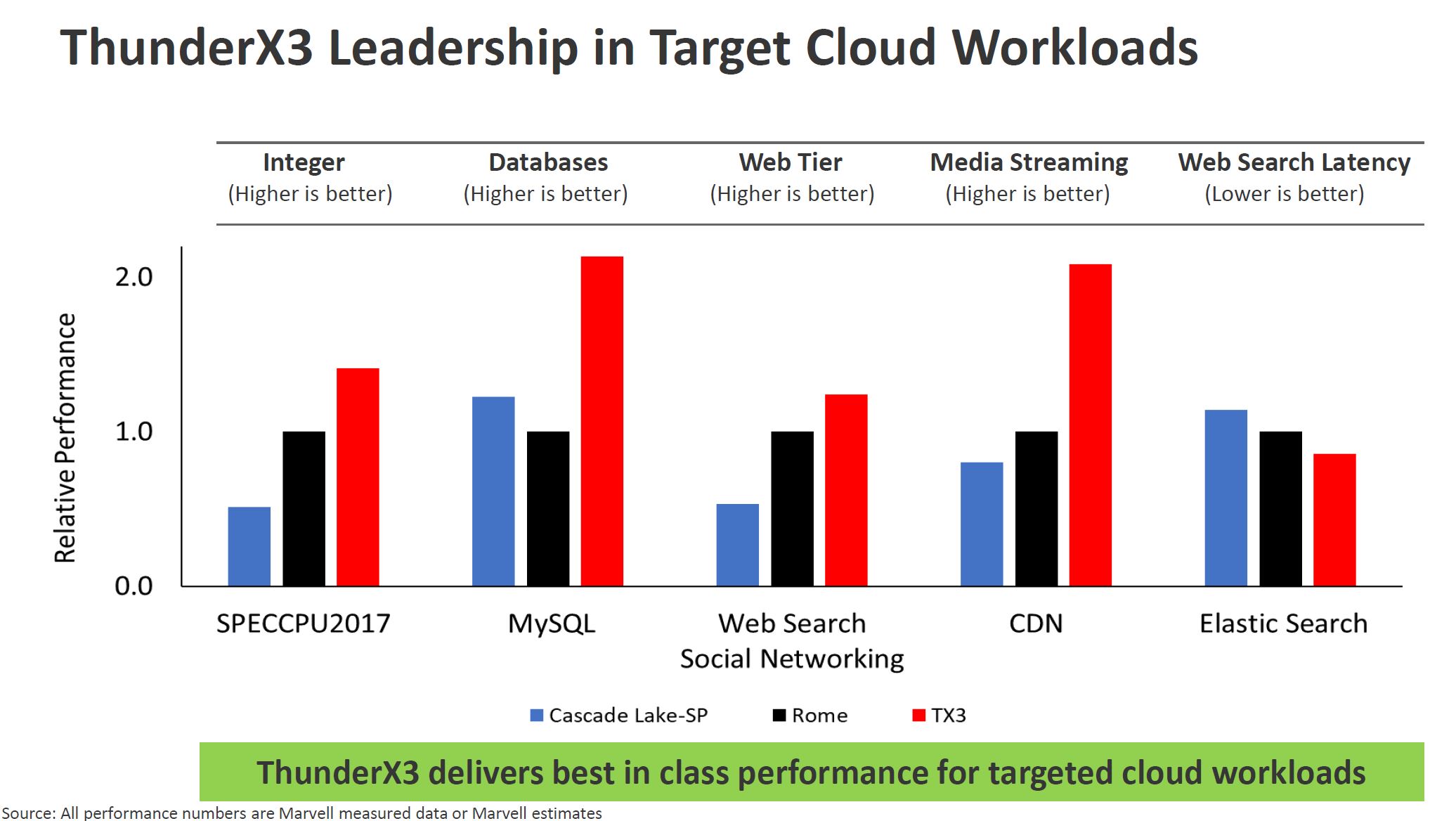
One of the big workloads that will be discussed later in this piece is also running Arm-on-Arm in the cloud. Running Arm programs on Arm CPUs can be significantly more efficient than running Arm on x86.
Marvell ThunderX3 HPC Prowess
On the HPC side, Marvell highlights its floating point performance and ability to run at higher clocks while running FP workloads. Although it says 4-way SMT is important, for many HPC workloads turning SMT=1 for TX2 was the better option. Memory bandwidth is interesting since Marvell is highlighting that it not only has strong FP units, but it can deliver data to the monolithic die via 8x DDR4-3200 controllers. Intel is currently at 6x DDR4-2933 per die. AMD EPYC 7002 is 8x DDR4-3200 but that memory access is through the I/O die. We expect AMD will still have more cache so that will impact many applications here as well.
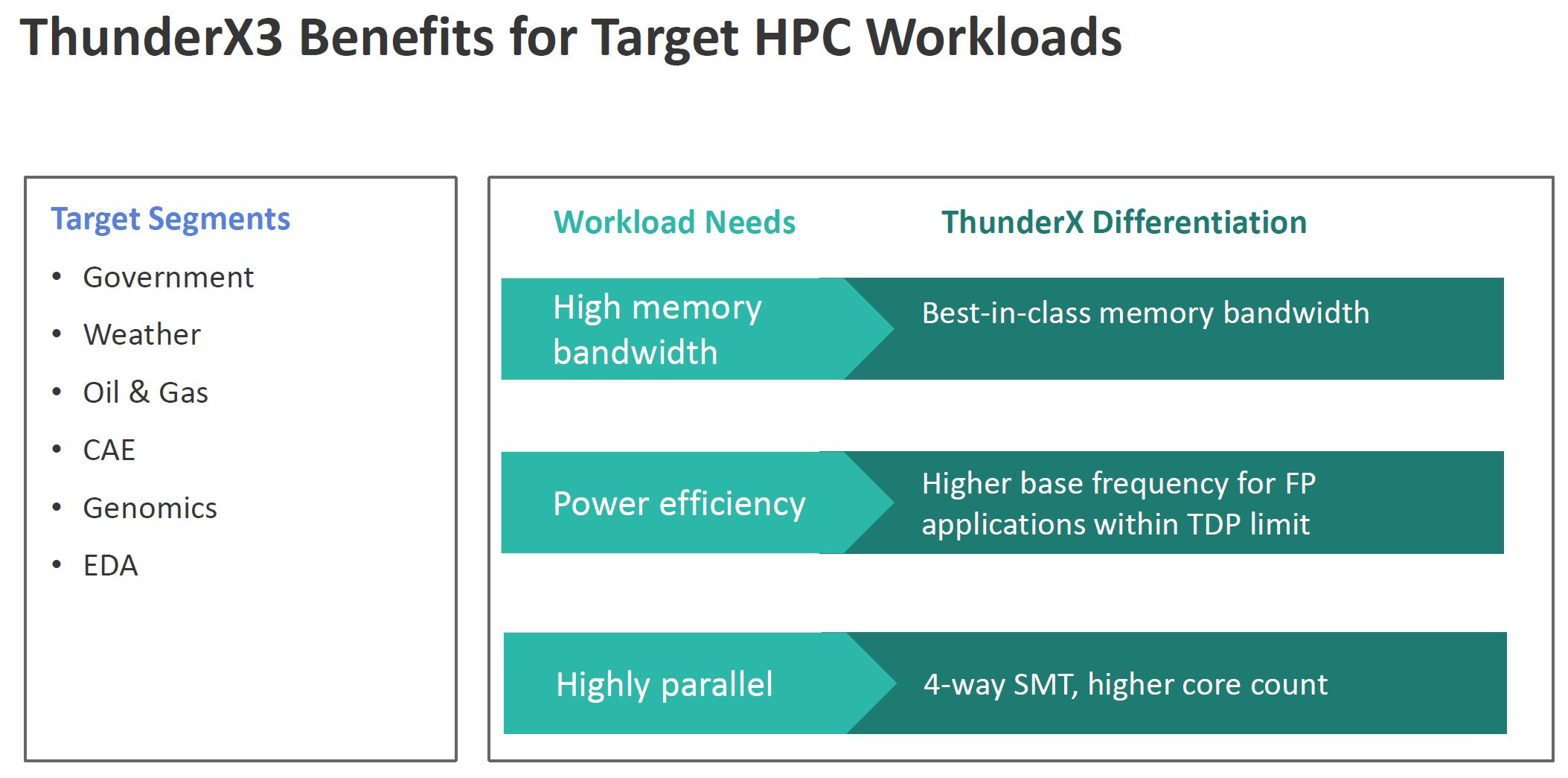
Perhaps one of the most interesting observations is that Marvell on the HPC workloads chart is comparing to AMD EPYC Rome, not Intel Xeon Scalable. That is a big change as we previously saw Intel as the measuring stick for the rest of the industry.
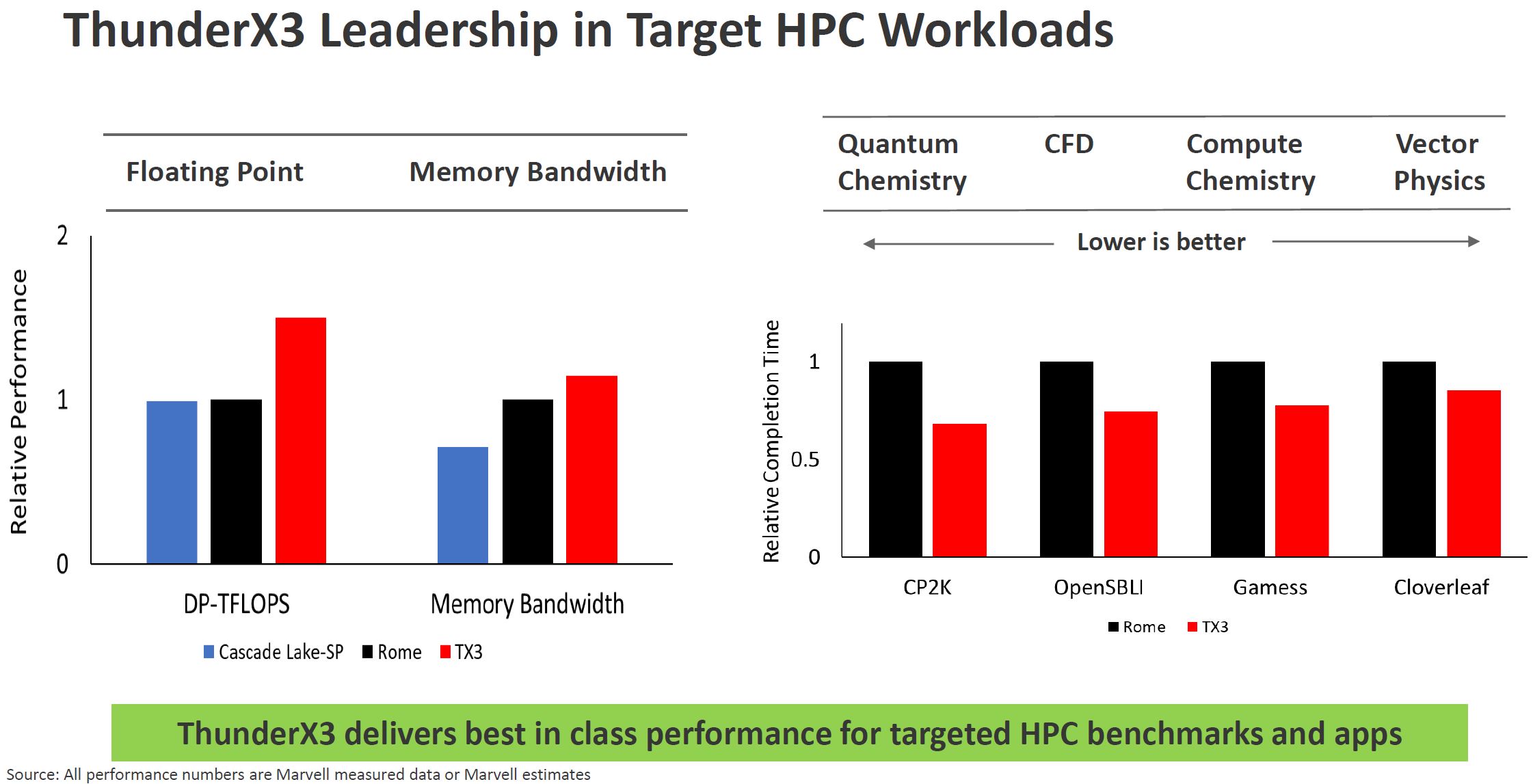
The ThunderX2 was designed to be an ARM HPC platform to a large extent. It appears as though Marvell is continuing its push into this market segment with TX3.
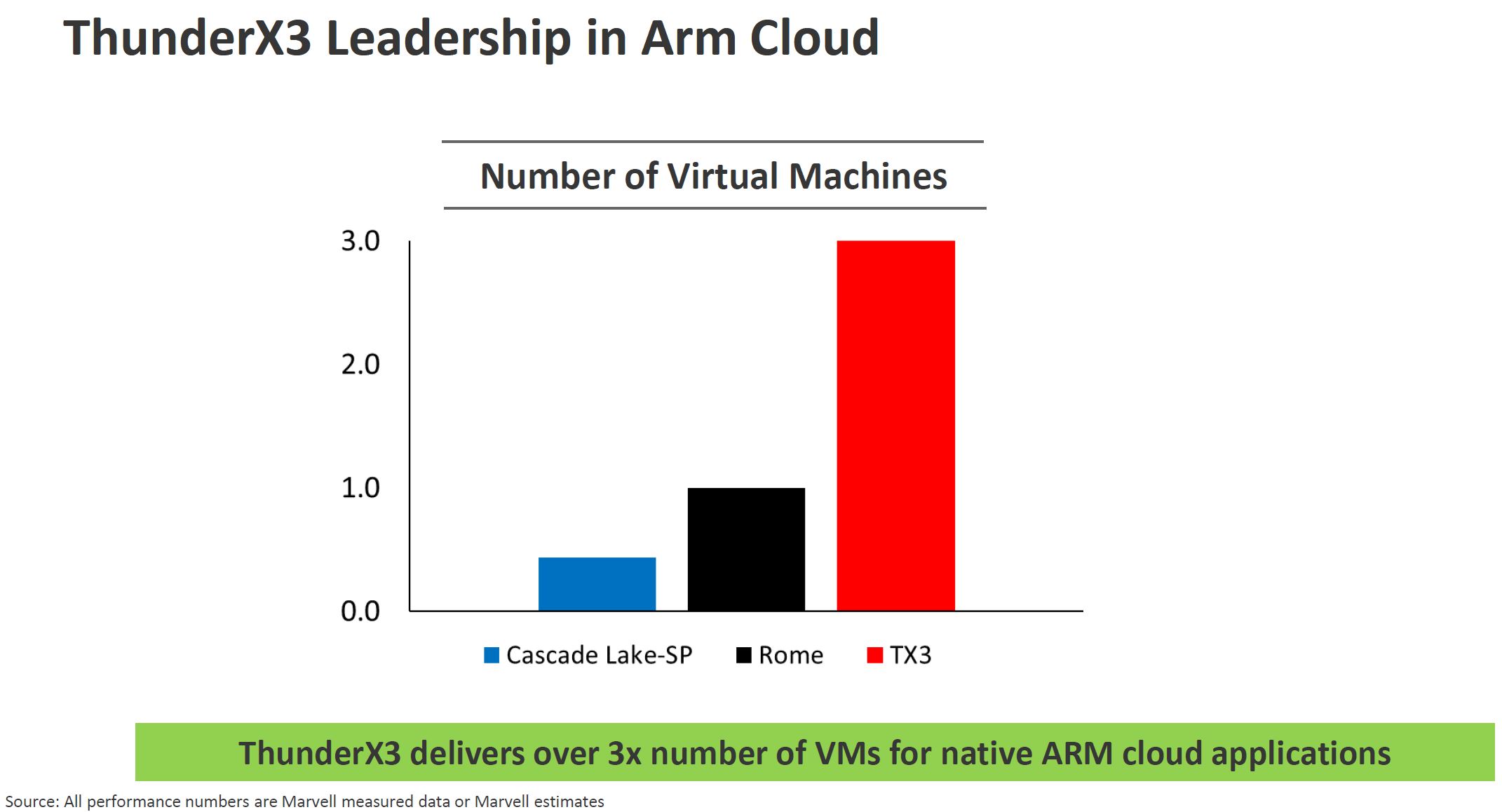
Marvell ThunderX3 for AoA Cloud
On the cloud side, we did a piece around our AoA Analysis Marvell ThunderX2 Equals 190 Raspberry Pi 4. It turns out that when you have to virtualize Android applications and emulate Arm on x86, you lose efficiency. You will notice that the number of VMs compared to x86 is labeled “Arm Cloud” for a reason.
Although the Marvell ThunderX3 CN110xx is a 240W part for 96 cores, 2.2GHz base, and 3.0GHz turbo, Marvell still says it will have better power efficiency than Rome or Cascade Lake-SP (2nd Gen Intel Xeon Scalable.)
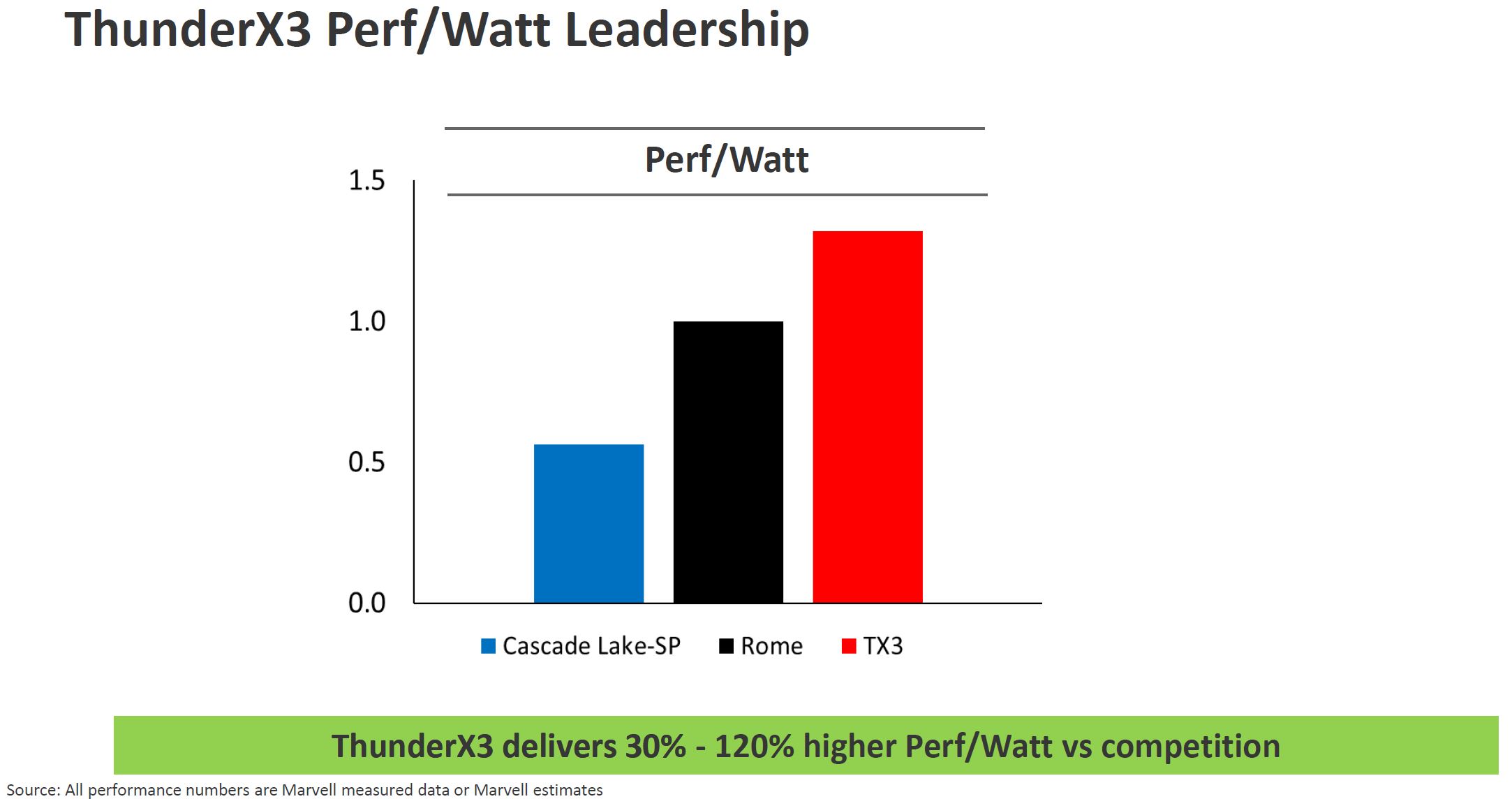
These are impressive numbers, but we need to see what is generating them.
Marvell ThunderX3 Appendix Disclosures
The disclosures of Arm CPUs are always something that we want to see. With the Ampere Altra Launch, we found comparisons that were based on using gcc all around. Here is the configuration disclosure slide for the charts above.

Here, we do not have numbers and citations to the numbers that Marvell is using for their Intel and AMD numbers. Ampere cited numbers then de-rated to gcc. If we use the literal citation we will notice that they are all using gcc 8 or gcc 9 and these numbers were measurements or estimates made by Marvell. Again, the gcc ecosystem is very large, but we still want to see additional optimized compiler results for Intel (icc) and AMD (AOCC) especially on the HPC side. One can contend that since this is more of a feature disclosure than a product launch, TX3 is still early in the cycle and these are more of estimates. Still, we want to see citations as a practice.
Final Words
Overall, if you were excited about Ampere Altra, you should be excited for ThunderX3 as well. Realistically, these will hit the market sometime after Cooper Lake hits for higher-end servers, just before Intel Xeon Ice Lake Xeons. On the AMD side, these will be more contemporaneous with the EPYC 7003 series “Milan” CPUs. What is certainly exciting here is that by the end of the year we should have several new platforms in the market.
If we were to project out, there is a good chance that ThunderX3 will have incrementally better system vendor support in this generation. If you look at ThunderX (1) to ThunderX2, the systems were much better and more vendors joined in. That was a big jump. TX2 to ThunderX3 is another large jump and we expect even more vendor platforms to make it to market. Having platforms is important as it helps activate more sales teams and also provides more form factors readily available for buyers. Large shops like Microsoft will work with vendors to make their own platforms, but for others, we need platform diversity. Marvell has shown this over the past generations which should serve them well here.
As always, stay tuned to STH. We will bring you benchmarks and hands-on impressions when we can.



{kind=link}
I think I will wait for real world benchmarks, saying you have 10x memory bandwidth or 10x Integer performance means nothing with out real world benchmarks to back it up. The N1 from both Ampere and Amazon is doing extremely well on all the common web benchmarks thrown at it.
But I see this 384 x2 vCPU per server ( Dual Socket ) unit to work favourably on cloud hosting.
😉 384 threads… are you sure this is a CPU and not a GPU?
One wonders if these ARM 96 core SMT4 processors make too much inroads against x86 if maybe AMD would dust off the verilog of Project K12, that custom in-house ARM core design brother to the Zen core only done up to execute the ARMv8a ISA instead of x86 ISA, could be brought out of mothballs. There was much news about maybe SMT and Jim Keller’s direct statements that the K12 and Zen teams where sharing plenty and that K12 maybe would support SMT(Speculation by many online) as well. But AMD is doing so well currently with x86 that it would take a lot more adoption of any ARM based products to change AMD’s mind. OpenPower Power8/9 supports SMT8 and SMT4(Power9) variants but that ThunderX3 is that as wide order superscalar as Power8/9 and really x86 is still so entrenched currently.
TSMC;s 5nm is sure going to be sweet for Apple and very likely many others but that’s more at Intel’s expense currently as AMD is at TSMC for the CCD parts of those Epyc/Rome and soon to be available Epyc/Milan designs on 7nm. But the ARM server market has had a slower uptake and that’s part of the reason that AMD moved K12 into mothballs and maybe never to be used.
They’re comparing a TDP part to a 205W TDP intel part and a 225W TDP AMD part. AMD has a 240W option (cTDP).
You can get high throughput by throwing a lot of threads at the problem. We’ve been there with Calxeda, seaMicro etc. The whole microserver thing is a niche because most workloads want robust 1T performance even in cloud. Calxeda also had great perf/watt but nobody really cared because perf/watt matters only after you lock perf at a particular place (some minimum IPC).
“STH asked about ThunderX2 in Exascale, specifically not having any wins on the first three US systems. ” That’s not surprising as TX2/Vulcan was in doldrums (Broadcom->Cavium->Marvell) and unclear what the future held. They’ve got no real volume: I expect even IBM power has more volume than TX2 which makes their market position very questionable. Nobody wants to rely on a supplier who might pull the plug.
A more significant question would be the lack of design wins in HPC more generally. They’ve had 3-4 successes, and those have been small/medium deployments, those who want to test alternatives. Plenty of HPC deployments don’t use GPUs. Nor is it that IBM power is winning tons of HPC deployments despite having a close tie-up with nVidia. Pre-launch Rome had more design wins than TX2/TX3 put together. A few issues are the lack of wide-vector simd units. I think they have goosed the peak flops metric by putting 4×128 FMA units (intel is 2×512, AMD is 2×256) and then leant on core counts. On real loads, wide vector SIMD actually gives you more throughput and is more efficient, which is why Fujitsu implements ARM SVE extensions.
“They’re comparing a TDP part to a 205W TDP intel part and a 225W TDP AMD part. ”
Make that “They’re comparing a *240W* TDP part to a 205W TDP intel part and a 225W TDP AMD part. ”
The other interesting thing is that HPC workloads that can be threaded to take advantage of 300+ threads are also likely to be amenable to GPU vectorization. It may just be that nobody has taken the effort yet.
When Cavium/Marvell describe such a narrow niche so small and so esoteric, then they can say they can have a “market win” anytime they want. Try to find a “real” ThunderX2 customer. Try to find a real cloud provider where you can provision TX2 on demand.
Try to buy a ThunderX2 platform? Good luck. Authorized resellers have to qualify you before hand, what a joke. By qualify, you have to tell them “exactly” what you are going to do with the platform, then they will decide if they want to sell them to you.
Anyone can’t just go out and buy an X2, and Cavium wants it that way. They are so obsessed about how it will be perceived, they want to control the message, from the purchase all the way to the press release.
And now there is a new entrant in the ARM server room, Nuvia. They are already talking trash publicly about how great they will be. But at least they are talking and engaging, unlike Cavium which hides in the closet and peeps out the door only when needed.
So until Cavium stops hiding in the closet, telling the market how their equipment should be perceived, and open it up to real world testing and public comparisons without interference, then I will believe them.
Until then its all sales talk and bluster. Put up or shut up.